
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 열역학
- 시뮬링크
- mendeley
- 포스코인턴
- 윈도우
- Fusion 360
- 파이썬
- simulink
- 모깎이
- 포스코
- reference manager
- 파워포인트
- github
- 클러스터링
- 머신러닝
- Python
- matlab
- ppt
- Desktop
- CAD
- PEMFC
- 기계공학
- 매트랩
- git
- 연료전지
- 멘델레이
- 스틸브릿지
- 비지도학습
- 군집화
- matplotlib
- Today
- Total
신군의 역학사전
[ML] 기계학습(Machine Learning) 개요 본문
1. 기계학습(Machine Learning) 이란?
머신러닝 텍스트북으로 가장 유명한 Tom M. Mitchell "Machine Learning" 에 따르면, 머신러닝은 특정 작업(T)에 대해 성능(P)를 향상시키기 위해 경험(E)에서 컴퓨터가 스스로 학습하는 과정을 말합니다.
"A computer program is said to learn form experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E" [Ref 1]
기계"학습"의 과정에서 말하는 학습 시스템은 환경(E)으로부터 데이터(D)를 얻어 모델(M)을 학습시키고, 이 모델의 성능을 성능지수(P)로 평가하는 과정으로 구성되며, 각각의 용어에 대한 정의는 아래와 같습니다.
환경(E) : 학습 시스템이 상호작용하는 대상 및 학습할 문제
데이터(D) : 환경과 상호작용을 통해 축적된 경험
모델(M) : 데이터를 모델링하는 학습 시스템의 구조
성능지수(P) : 학습 시스템의 성능 평가 지표 & 학습 시스템이 목표를 이루기 위하여 최적화 해야하는 대상. 대표적인 성능지수로는 손실(loss)와 보상(reward) 등이 있음.
이를 수식적으로 표현해보자면 아래와 같습니다. 데이터 X와 Y의 관계를 f라는 모델로 설명할 수 있다면, 이를 Y= f(X)로 모델링할 수 있습니다. 다만 이는 우리가 모든 데이터에 대한 정보를 갖고 있을때의 모델이기 때문에, 우리는 올바른 모델을 학습을 통해 추정해야합니다.

학습을 통해 추정한 모델이 f^이 되며, 추정모델에 따른 Prediction값은 Y^이 됩니다. 즉, 올바른 학습을 통해 f와 f^간의 차이를 최소화할 수 있다면, 실제 값인 Y와 모델에 의한 예측값인 Y^간의 차이가 적어 좋은 성능을 낼 수 있습니다.
하지만, f^은 f에 대한 완벽한 추정이 될 수 없는데, 이는 모델의 예측값인 Y^이 X에 대한 함수이기도 하지만, 노이즈에 대한 함수이기도 하기 때문입니다. 즉, Y는 아래와 같이 표현할 수 있으며

이를 Mean Square Error와 같은 모델 성능 지표에 대입하여 표현해보면 아래와 같이 정리됩니다.

노이즈에 대한 기댓값은 0이 되기 때문에, 노이즈와 곱으로 표현된 항들은 쉽게 0으로 소거됨을 활용하면 어렵지 않게 전개가 가능합니다. 정리된 식에서 앞쪽 Term을 Reducible Error, 뒤쪽 Term을 Irreducible Error라 하며, 모델 학습을 통해 Reducible Error Term을 최소화할 수 있습니다.
2. 모델(Model)
우리의 목적은 여러 머신러닝 기법들을 활용해 실제 데이터를 잘 설명할 수 있는 모델을 구성하는 것입니다. 이러한 모델의 추정과정은 크게 Parametric Method와 Non-Parametric Method로 분류할 수 있습니다.
Parametric Method는 모델의 형태를 사전에 정의하고, 그에 필요한 파라미터들을 추정하는 방식을 말합니다. 예를들어, 특성 데이터셋이 선형 거동을 보일 것이라 가정한다면, 데이터를 바탕으로 선형함수를 구성하는 기울기와 절편 2가지 파라미터에 대한 값을 추정해낼 수 있습니다.


다만, 위의 데이터를 보고 누군가는 선형으로, 또다른 누군가는 다항함수로 모델의 형태를 가정할 수 있는데, 모델의 형태를 잘못 가정할 경우 실제 데이터를 잘 설명하지 못하거나 과적합(Overfitting)이 발생할 수 있다는 단점이 있습니다.
Non-Parametric Method는 모델의 형태를 사전에 정의하지 않고, 데이터의 패턴을 최대한 반영하는 방식으로 모델을 만들어나가는 과정을 의미합니다. 아래의 왼쪽 그림처럼 모델의 형태를 정해놓고 추정을 하는 경우(Parametric Method), 실제 데이터를 잘 설명하지 못하는 영역도 필히 발생하게 되는데, 이러한 문제점들을 어느정도 해결할 수 있다는 장점이 있습니다.


다만, 데이터 기반 추정법이므로, Parametric Method에 비해 학습에 필요한 데이터의 수가 월등히 많으며, 이로인한 과적합(Overfitting)이 발생할 수 있다는 단점 역시 있습니다.
3. 기계학습(Machine Learning)의 분류
머신러닝 기법을 분류하는 기준은 여러가지가 있지만, 학습 종류에 따른 분류가 가장 일반적이며, 이에 따른 분류는 아래와 같습니다. 항상 딥러닝의 포지션이 어떻게 될까 궁금했었는데, 제가 참고한 텍스트북에 이를 직관적으로 보여주는 Figure자료가 있어 함께 첨부합니다.

3.1 지도학습(Supervised Learning) : Estimate an unknown mapping from known input and target ouput pairs.
지도학습(Supervised Learning)이란, 정답이 있는 데이터를 기반으로 학습하는 방식을 말합니다.
즉, 데이터에 라벨링이 되어있어야 합니다. 사람이 지정해놓은 라벨링에 따라 학습을 진행하게 되므로, 인간의 의사가 충실히 반영되는 학습 방식이라 할 수 있으며, 대표적인 예시로는 회귀(Regression)와 분류(Classification) 기법이 있습니다.
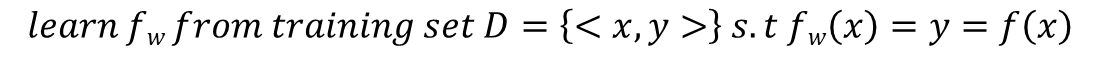
회귀 문제의 경우 예측값인 y가 연속적인 분포를, 분류 문제의 경우 이산적인 분포를 띄게 되며, 지도학습의 최종적인 목표는 아직 관측하지 않은 데이터에 대해 올바른 대답을 하는 것 이라 정리할 수 있습니다.
3.2 비지도학습(Unsupervised Learning) : Only input values are provided
비지도학습(Unsupervised Learning)이란, 정답이 없는 데이터를 기반으로 학습하는 방식을 말합니다.
데이터 라벨링 없이, 모델 스스로 데이터 간의 패턴이나 군집을 발견하도록 학습을 진행하여 인간의 개입이 최소화된 학습방식이라 할 수 있습니다. 대표적인 예시로는 클러스터링(Clustering)과 주성분분석(PCA)등이 있습니다.
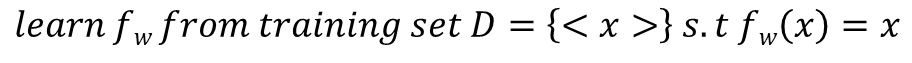
3.3 강화학습(Reinforcement Learning)
강화학습(Reinforcement Learning)은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 방식을 말합니다.
강화학습은 지도학습과 유사하게 출력을 알려주긴 하지만, 정답이 아닌 평가값(Reward)을 알려준다는 점에서 차이가 있습니다. 즉, 이쪽방향이 "맞다 vs 아니다"가 아닌 "좋다 vs 나쁘다"에 대한 정보를 제공하며, 이러한 보상(Reward)을 최대화하는 방향으로 학습이 진행됩니다.

강화학습에 대한 내용은 별도의 카테고리를 통해 내용을 다시한번 정리할 계획인데, 해당 게시글에서 좀 더 내용을 자세하게 담아보겠습니다.
Reference
[1] "Machine Learning", Tom M. Mitchell
[2] "An Introduction to Statistical Learning", Gareth james
[3] "Understanding Deep Learning", Simon J.D. Prince
'Machine Learning > Tools & Concept' 카테고리의 다른 글
| [ML] 파라미터(Parameter)와 하이퍼 파라미터(Hyperparameter) (0) | 2024.11.01 |
|---|---|
| [ML] 분류 모델 평가 지표 - 오차행렬 (Confusion Matrix) (1) | 2024.10.28 |
| [ML] 엘보우 메소드 (Elbow method) (3) | 2024.10.25 |

